9.1 Choosing the correct test
It is important that you learn how to identify which inferential statistic you should perform. This chart can help you determine what statistical test to perform. Note that on the right dark red boxes are parametric tests, light red boxes are non-parametric tests, and white boxes will not be covered in this class at all (in fact, there are many others not even shown that we won’t cover!). Data types are indicated in either blue (continuous), green (categorical), or teal (both). Number of variables or levels of the variables are either 1 (light orange), 2/2+ (orange), or 3+ (dark orange). Between-subjects designs, meaning designs with different participants in each group, are in black whereas within-subjects designs, meaning designs with the same participants in each group, are in light grey.
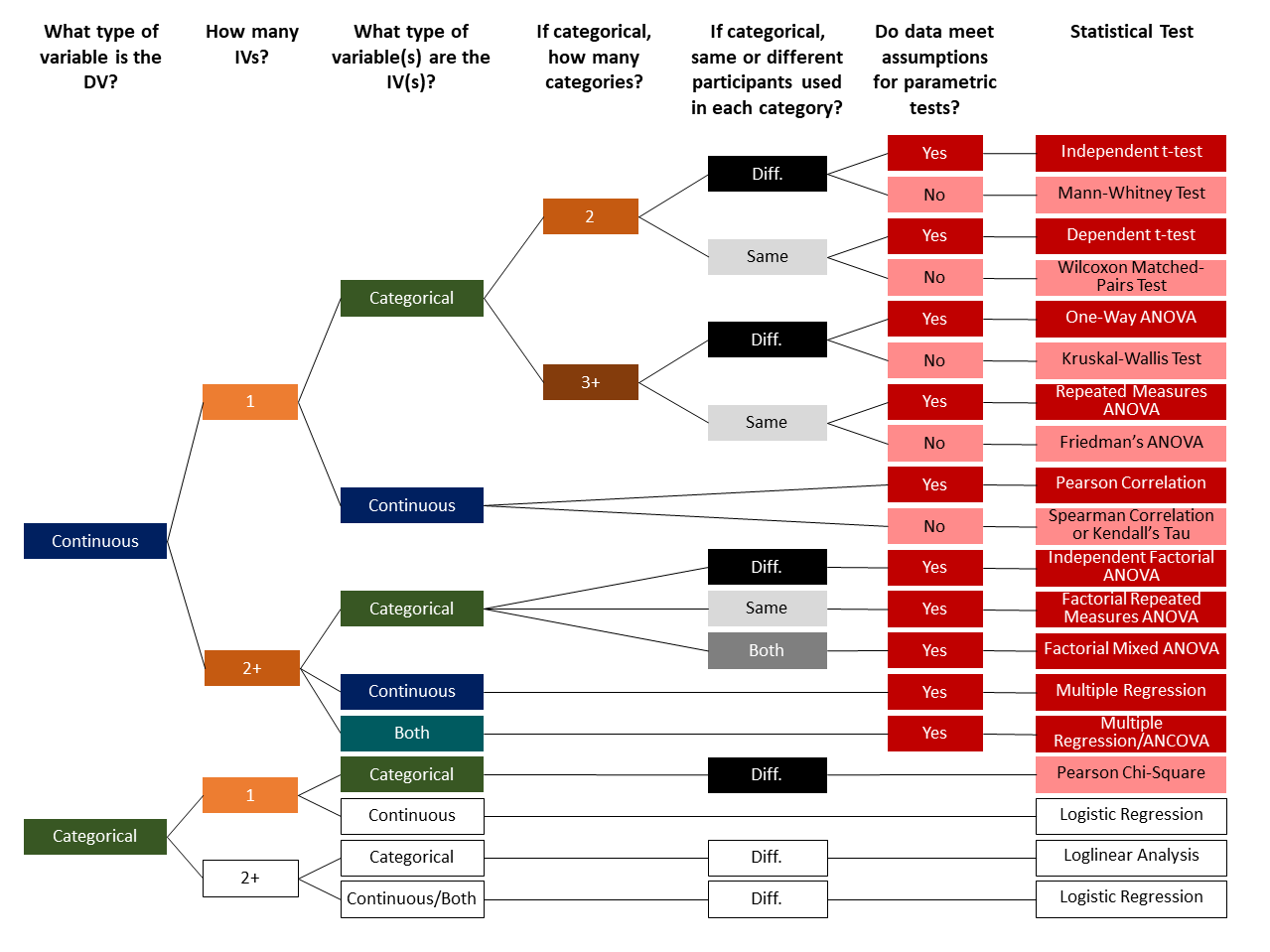
Note: if you are a student in PSYC 290 or 790, you have access to a high-resolution PDF of this chart on Canvas.
You may find it helpful to first think whether you have a between-subjects or a within-subjects design. If you have groups, are participants in the same conditions (within-subjects) or different conditions (between-subjects)? Then that narrows down the possibility of what inferential statistic you would use. For example, if you know you have a repeated measures design with only one IV, then it’s either a dependent t-test or repeated measures ANOVA depending on whether there are 2 or 3+ categories to the IV.
First, you need to determine what level of measurement your dependent variable (DV) is. We will only be covering statistical tests that have one dependent variable. Therefore, you need to know whether the variable is categorical (i.e., nominal or ordinal) or it’s continuous (i.e., interval or ratio).
Go back to Chapter 2 “Levels of Measurement” to refresh yourself on the difference between categorical and continous variables! This is very important information to remember throughout this course. Furthermore, you need to know exactly how things are measured or manipulated to determine the level of measurement.
Next, you need to determine how many independent variables (IVs) there are and then what level of measurement your IV(s) are. In the case of a single categorical IV, we also need to know how many levels there are to the IV (i.e., how many categories there are). For categorical variables, we also need to know if the participants are different (i.e., between-subjects) or the same (i.e., within-subjects) within each level of the category.
Lastly, for many of the statistical tests we need to know whether we meet the assumptions of parametric tests. If we don’t meet the assumption, then there are alternative tests we can perform. We’ll learn about assumption checking in the next section of this chapter.
Checking assumptions is very important to know which exact test to perform. For now, we’ll assume the assumptions are met, but we’ll learn more about checking assumptions in the next chapter.
Another tool that can help you determine the statistical test you want to perform is https://stathand.net/
We can both forward map and backwards map with the chart above.
Forward mapping involves understanding your data and your research question and then determining what statistical test to perform. Forward mapping is mostly what you need to understand how to do!
Backwards mapping involves determining what kind of data is needed to perform a particular statistical test. This is more for educational and understanding purposes and generally is not how you analyze data. You may also use it to justify which statistical test you performed.
Let’s do some examples of forwards mapping. You may want to read the example and try your hand at it first and then check your answers!
Forward mapping: Choose the correct test
A researcher is interested in understanding whether athletes have higher English scores than non-athletes. In other words, what is the effect of athletic status on English test scores?
What is the DV? What is the level of measurement? It’s English test scores, which is a continuous variable.
How many IVs are there? We only have one IV, and it is athletic status.
What is the level of measurement of the IV? Athletic status is a categorical variable.
How many categories to the IV? Athletic status is measured as either athlete or non-athlete, so there are 2 levels.
Are the same or different participants used in each category? People can either be an athlete or not an athlete, but they can’t be both, so this is a between-subjects variable (aka “different”).
Do data meet the assumptions for parametric tests? We don’t know. We would need to test this. For now, let’s assume we meet the assumptions.
Statistical test? Independent t-test
A researcher is interested to know whether people perform better on the exam at the start, middle, or end of the semester. The researchers has all participants complete all three exams.
What is the DV? What is the level of measurement? In this case, the exam is our DV and it’s a continuous variable.
How many IVs are there? We only have one IV, and it is time of the exam.
What is the level of measurement of the IV? The time of the exam is a categorical variable.
How many categories to the IV? Type of test has three categories: start, middle, or end of the semester.
Are the same or different participants used in each category? Although the researcher could have designed a between-subjects design, this particular study has all participants participate in all conditions, so it is a within-subjects design (aka “same”).
Do data meet the assumptions for parametric tests? We don’t know. We would need to test this. For now, let’s assume we meet the assumptions.
Statistical test? One-way repeated measures ANOVA
Backwards map: Determine the data you need
Let me start off by saying we don’t normally do this. We perform the test based on the data we have. But in our learning, we also want to ensure we learn all the tests. Imagine I gave you a dataset and wanted you to perform two different tests that I told you about.
Here are the variables in the dataset:
- Mile time (continuous variable ranging from 5-30 minutes)
- BMI (categorical variable of underweight, normal, or overweight)
- Happiness at the start of the semester (continuous variable ranging from 0-10)
- Happiness at the end of the semester (continuous variable ranging from 0-10)
If I told you I wanted you to perform a dependent t-test, what data would you use?
- Assuming we meet the assumptions for a parametric test, we need to find a situation in which we have 1 continuous variable and 1 categorical variable with 2 levels in which participants are the same within each category (i.e., within-subjects variable).
- We only have three continuous variables: mile time and our two happiness variables.
- If we rethink happiness, we can realize that it’s really a within-subjects variable. We are measuring happiness (our continuous DV) across two time points (start and end of the semester).
- Therefore, we could perform a dependent t-test with our two happiness data points and see whether happiness differs across time in the semester.
If I told you I wanted you to perform a one-way independent ANOVA, what data would you use?
- Assuming we meet the assumptions for a parametric test, we need to find a continuous DV and a single categorical IV with 3 or more levels in which participants are different across categories (i.e., between-subjects design).
- We only have three continuous variables: mile time and our two happiness variables.
- We only have one categorical variable (BMI), and it has 3 levels: underweight, normal, overweight.
- Now this is where we need to think critically. What would be the most interesting test here? How BMI affects happiness or how BMI affects mile time? Weight and performance on running a mile seem to make most sense here. Therefore, we could look at how BMI affects mile time. Though keep in mind we are not randomizing here and so this is not an experimental design!