13.5 ANCOVA
ANCOVA (ANalysis of COVAriance) examines the difference in means between three or more groups, while controlling for or partialling out the effect of one or more continuous confounds or covariates.
Some definitions: A confounding variable is a variable that affects or is related to both the independent and dependent variable. A covariate variable is a variable that only affects or is only related to the dependent variable.
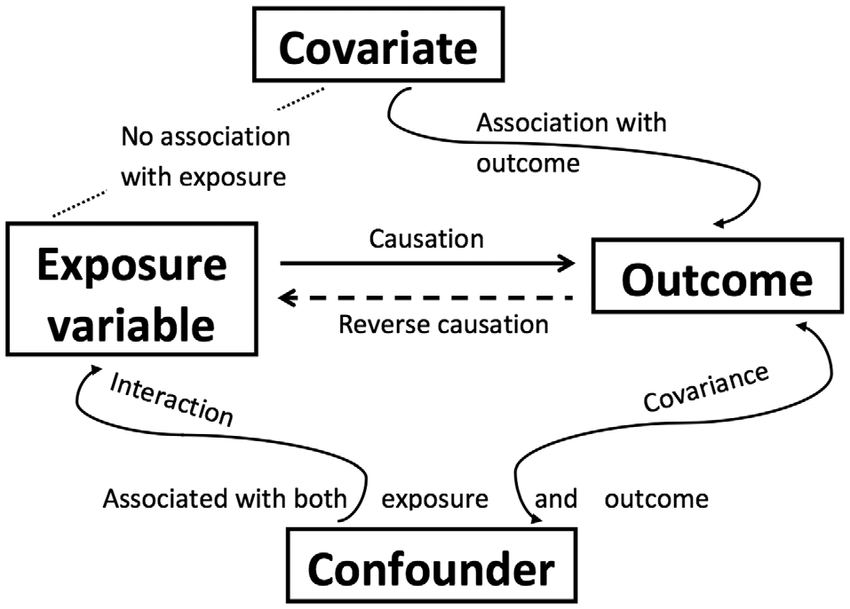
There are two main reasons for including covariates:
To reduce within-group error variance: Remember that to get a larger F-statistic, we need to maximize between-groups variance and minimize within-groups variance. Adding covariates can sometimes minimize within-groups variance if that covariate helps explain some of the within-group variance.
Elimination of covariates: Sometimes there are other variables that also explain our outcome variable. We want to look at the effect of another variable on the outcome while removing or eliminating the other variables (confounds) that also explain our outcome variable.
Step 1: Look at the data
Let’s run an example with data from lsj-data. Open data from your Data Library in “lsj-data”. Select and open “ancova”. This data is fictional data from a health psychologist who was interested in the effect of routine cycling (1 = driving, 2 = cycling) and stress (1 = high, 2 = low) on happiness levels, with age as a covariate. Notice how this is a 2x2 independent factorial design with a covariate!
I’m going to skip some of the looking at the data stuff. Look at how the data is setup in this example and check your descriptive statistics first!
Here’s a video walking through the ANCOVA test.
Step 2: Check Assumptions
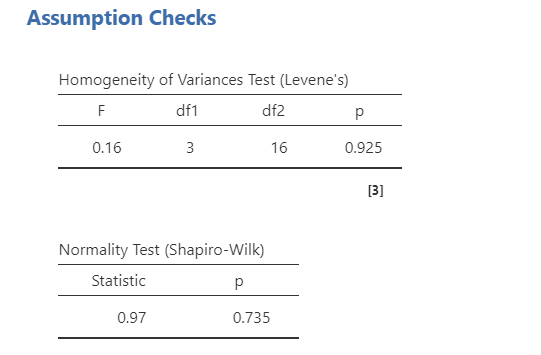
The ANCOVA has two additional assumptions we’ll get to next; otherwise, it also has the same assumptions as the one-way ANOVA (i.e., normal distribution, homogeneity of variance, interval or ratio DV, scores are independent between groups). Let’s test those first. Shapiro-Wilk’s test was not statistically significant (p = .735), the Q-Q plot looks good, skew and kurtosis were fine, and distribution looks fine; therefore, we’ve satisfied the assumption of normality. Levene’s test was not statistically significant (p = .925); therefore, we’ve satisfied the assumption of homogeneity of variance.
The ANCOVA has two additional assumptions.
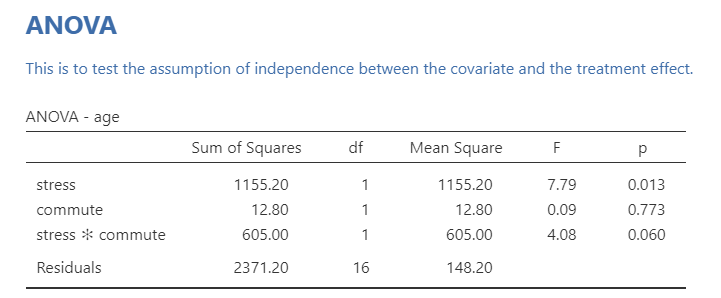
Independence of the covariate and treatment effect
When the covariate and treatment effect are related, then we can have incorrect F-statistic values. However, this is only important in experimental designs. In quasi-experimental designs, this is often violated and you just have to interpret results accordingly.
- If you do have an experimental manipulation with a covariate, you can test this assumption by running a one-way ANOVA but with your experimental manipulation as your IV or group variable and your covariate as your DV. If there is a significant F-statistic, then you have violated this assumption. In this case, one of our IVs (stress) is significantly related to age, so we violate this assumption. This suggests that age is not a covariate, but more appropriately a confounder, which necessitates a different type of analysis not described here (mediation).
Homogeneity of regression slopes
The second additional assumption is that the relationship between the covariate and the dependent variable is similar for all levels of the independent variable (homogeneity of regression slopes). We can test this by adding an interaction term between the covariate and each independent variable in jamovi under the Model drop-down menu. Age does not significantly interact with either stress (p = .520) or commute (p = .771).
Step 3: Perform the test
To perform an ANCOVA in jamovi, select ANCOVA under the ANOVA analysis menu.
Move your dependent variable
happinessto the Dependent Variable box, your independent variablesstressandcommuteto the Fixed Factors box, and your covariateageto the Covariates box.Select \(\omega^2\) as your effect size.
Under Assumption Checks, select all three assumption checks:
Homogeneity test,Normality test, andQ-Q Plot.Under Post Hoc Tests, move both of your independent variables over, select the
Tukeycorrection and selectCohen's dfor your effect size.Under Estimated Marginal Means, move each of your independent variables over into its own term box. Also include combinations of your independent variables if you have an interaction term in your model. Select both plots and tables, select
Observed scores, and de-selectEqual cell weights.
Step 3: Interpret results
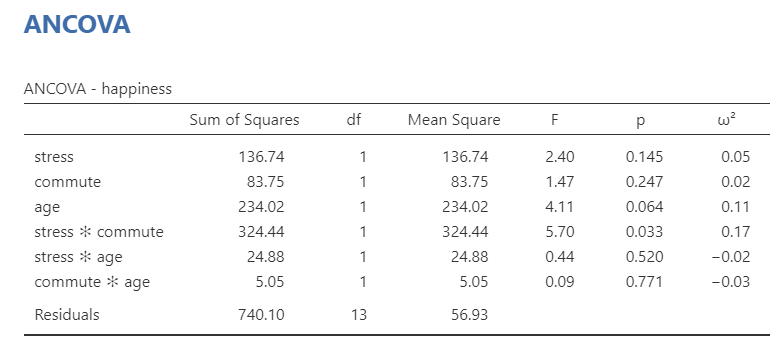
The ANCOVA table shows that both independent variables (stress and commute), the interaction term (stress * commute*), and the covariate (age) are statistically significant. Therefore, we can look at our post hoc tests to find where the differences are.
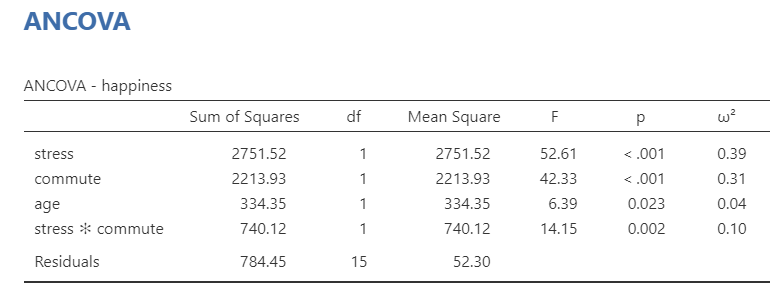
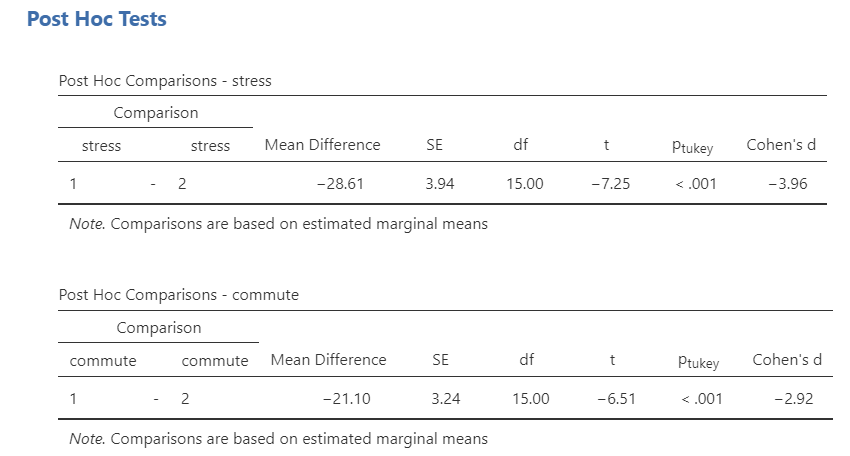
Technically, we don’t need to look at the post hoc table much in this example. Because there are only two groups, we already know one group will have higher means than the other group if the F-test is significant. In fact, check this out: the square root of our F-statistic is equal to the t-statistic in our post hoc table. Neat!
Post hoc tests show that low stress had higher happiness than high stress, and that cycling had higher happiness than driving. We can also look to the estimated marginal means tables and plots for information for reporting.
Write up the results in APA style
Last, we can write-up our results! Reporting ANCOVA is very similar to reporting an ANOVA test (in this case an independent factorial ANOVA) except that we also report the effect of the covariate, as well. Here’s an example write-up:
We conducted a study examining how stress and commute affect happiness levels in a 2 (stress: high or low) x 2 (commute: cycling or driving) independent factorial design. Furthermore, we collected data on age as a covariate of our study. We satisfied all assumptions of the ANCOVA except that age was in fact a confounding variable in that it relates to our independent variable of stress. Despite failing to meet this assumption, we proceeded with the ANCOVA analysis.
There was a significant main effect of stress on happiness such that participants in the low stress condition (M = 68.45, SE = 2.55) reported significantly greater happiness than participants in the high stress condition (M = 39.85, SE = 2.55), F (1, 15) = 52.61, p < .001, \(\omega^2\) = .39. There was also a significant main effect of commute on happiness such that participants who commuted via cycling (M = 64.70, SE = 2.29) reported significantly greater happiness than participants who commuted via driving (M = 43.60, SE = 2.29), F (1, 15) = 42.33, p < .001, \(\omega^2\) = .31. There was a significant interaction between stress and commute type such that happiness levels were similar in the low stress condition for both commute types, but happiness was significantly higher for participants who cycled versus those who drove in the high stress condition, F (1, 15) = 14.15, p = .002, \(\omega^2\) = .10. Furthermore, age was a significant covariate of our dependent variable, F (1, 15) = 6.39, p = .023, \(\omega^2\) = .04.